 Featured
Featured01
AI & Engineering Productivity
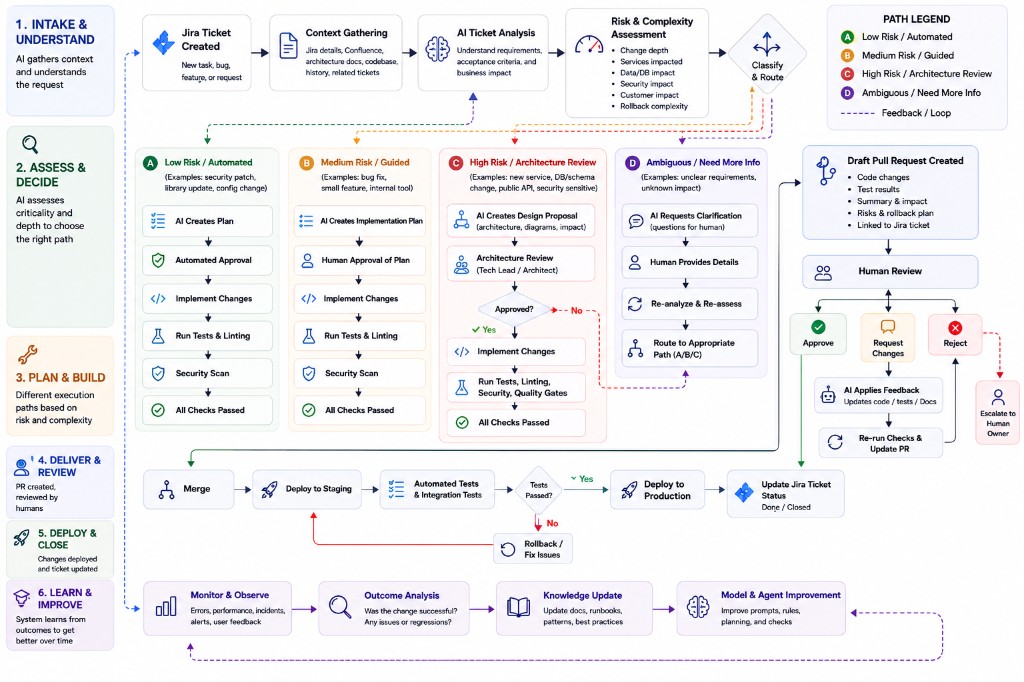
How We Reduced Developer Lead Time by 68% Using an AI-Powered Engineering Agent
Engineering teams spent significant time on activities surrounding software development rather than solving business problems.
- Average ticket lead time decreased by approximately 68%
- Routine work often moved from ticket to pull request within minutes
- Engineers spent more time on architecture and product, less on context gathering